유사도검색
- 엘라스틱 서치에서의 검색 결과는 유사도 점수가 반영되며
_score로 나타난다
유사도 모듈
- 인덱스마다 다른 유사도 점수 계산 방식을 취할 수 있다.
- 인덱스 입력 시 유사도 모듈을 선택 해서 입력 가능하다.
BM25
- 루신 기반의 tf idf 모듈을 기반으로 만들어진 유사도 모듈
- 해당 모듈은 default값이다.
- tf는 하나의 doc에서 같은 단어가 몇번 나오는지에 대한 점수
- tf idf에서 tf의 가중치를 줄여서 정확성을 높인다.
- 홍진호,홍진호의 생일은 다들 아시다시피 2월 22일이다, 2월 22일이다</br> 그는 2등을 두번 했다 2등을 두번했다.
- 위와 같을 때 자주나온다고 점수 높아지면 안됨. 실생활에서 이런경우 많음.
그 외의 모듈 들
- 루신에서 지원하는 유사도 모듈들을 다 지원한다.
수학적으로 자신 있다! 싶으면 스크립트로 직접 짜도된다.
사용자 정의 모듈
- default로 각 모듈을 취하는 방법도 있지만 유사도 모듈의 매개변수를 조정함으로써 가중치 계산 법을 수정 할 수도 있다.
{
"settings" : {
"index" : {
"similarity" : {
"my_similarity" : {
"type" : "DFR",
"basic_model" : "g",
"after_effect" : "l",
"normalization" : "h2",
"normalization.h2.c" : "3.0"
}
}
}
}
}
유사도 모듈 설정 관련 문서
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
scoring
- 유사도 모듈의 설정에 따라 각 검색 시 마다 _score로 유사도를 판단하여 검색 함
How Shards Affect Relevance Scoring in Elasticsearch
- 스코어 계산은 default 로 샤드 기준으로 계산을 함
- 샤드에 document가 어떤 분포로 들어가느냐에 따라 score가 다르게 나올 수 있음
Function score query
- 검색 결과와 임의로 조정한 score 값을 합쳐서 결과를 출력
- result example
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"functions": [
{
"filter": { "match": { "test": "bar" } },
"random_score": {},
"weight": 23
},
{
"filter": { "match": { "test": "cat" } },
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score" : 42
}
}
}
- 옵션은 score_mode, boost_mode, weight
- score_mode
- sub query 에서 나온 결과를 어떻게 조합하는가
- multiply(default), sum, avg, first, max, min
- boost_mode
- sub query로 나온 값과 main query로 나온 값을 어떻게 조합할 것인가를 결정
- multiply(default), sum, avg, first, max, min
- weight
- weight 값이 존재할 경우 해당 weight 값으로 score 값을 곱함
- score_mode
- 함수는 field_value_factor, script_score, Decay functions
- field_value_factor
- 해당 필드에 값이 존재할 경우 그 값을 score 에 포함시킴
- 해당 함수의 boost 값으로 추가되는 값을 조정할 수 있음
- missing 은 해당 필드가 존재하지 않을 경우 들어가야 하는 값을 정의함
- 결과는 음수가 되면 안됨
- log를 사용할 경우 인자 값이 0이 되면 연산이 되지 않기 때문에 주의해야 함
- log1p, log2p를 사용하여 해당 문제를 회피할 수 있음
- script_score
- painless로 작성 된 스크립트를 이용해서 score 에 포함 될 값을 선정
- Decay functions
- 필드의 값이 기준 값에 얼마나 떨어져있는지를 이용해서 얼마나 score를 조작할 것인가를 선정
- 종류는 gauss, lin, exp
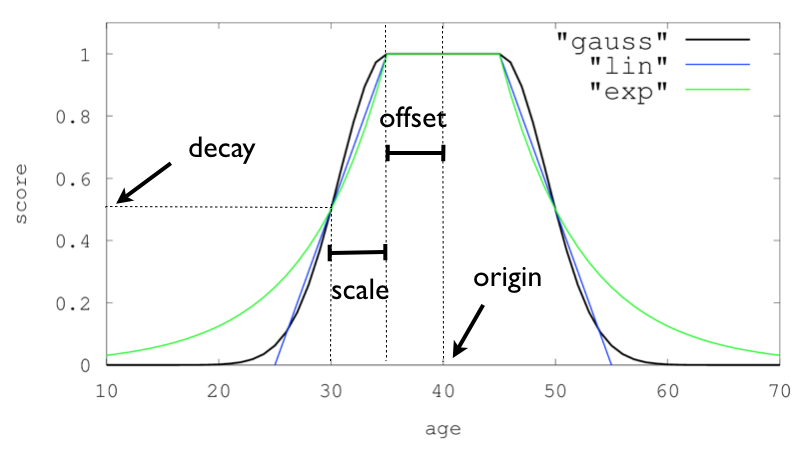
- date 필드에 적용하여 시간순으로 정렬할 수 있음
- field_value_factor
※ boost및 weight 는 상대적이다.
rank_feature
- 7.0 버전에서 새로 생긴 field 와 query
- 필드는 rank_feature 와 rank_features
- 필드에 저장되어 있는 값을 기존 score에 더하는 방식으로 score 조정
score = bm25_score + satu(pagerank)
- 7.0에서 추가된 Faster top k retrieval 을 support 하기 위한 기능으로 추정됨
this query has the benefit of being able to efficiently skip non-competitive hits when track_total_hits is not set to true
- 제공되는 함수들은 saturation, logarithm, sigmoid
saturation = S / (S + pivot) logarithm = log(scaling_factor + S) sigmoid = S^exp^ / (S^exp^ + pivot^exp^)
- Function score query 에서 값을 조정하는 것과 차이점이 뭔지 모르기 때문에 더 찾아봐야 함
분석
- 색인 시 역색인으로 뽑기위한 과정을 분석으로 칭함.
- 분석기
- character filter
- tokenizer
- token filter
url 단독 분석테스트
- analyzer 테스트
curl -XPOST localhost:9200/_analyze?pretty -H "Content-Type: application/json; charset=utf-8" -d '
{
"analyzer":"whitespace",
"text":"The quick brown fox."
}'
- 토크나이저, 필터 구분
curl -XPOST localhost:9200/_analyze?pretty -H "Content-Type: application/json; charset=utf-8" -d '
{
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ],
"text": "Is this déja vu?"
}'
analyzer설정 방법
- 기본적으로 analyzer는 character filter, tokenizer, token filter등을 조합해 index 설정 시 만든다.
curl -XPUT localhost:9200/new_index/?pretty -H "Content-Type: application/json; charset=utf-8" -d '
{
"settings": {
"analysis": {
"analyzer": {
"new_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ]
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "new_analyzer"
}
}
}
}'
- 해당 인덱스에서 해당 analyzer 테스트 가능하다
url -XGET localhost:9200/new_index/_analyze?pretty -H "Content-Type: application/json; charset=utf-8" -d "
{
\"analyzer\":\"new_analyzer\",
\"text\":\"test? it's Done\"
}"
built-in anlayzer
- 자주 쓰는 analyzer 설정은 엘라스틱 서치가 미리 정의 해놨는데 built-in analyzer라 한다.
- type으로 구분하며 custom이 아니다.
- 설정을 변경하여 customizing가능하다.
ex) standard analyzer를 커스터마이징 함.
curl -XPUT localhost:9200/new_index/?pretty -H "Content-Type: application/json; charset=utf-8" -d '
{
"settings": {
"analysis": {
"analyzer": {
"std_english": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std_english"
}
}
}
}'
built-in analyzer 종류
Standard analyzer
- 표준 analyzer
- 토큰화에서 쪼개고 소문자화 함.
- 옵션
- max_token_length : 토큰당 최대길이
- stopwords : 제외시킬 문구 종류
- stopwords_path : 제외시킬 문구를 정리한 파일경로
Simple Analyzer
- 소문자 토크나이저로 이루어짐
- 옵션 x
Whitespace Analyzer
- 공백 토크나이저로 이루어짐
- 옵션 x
Stop Analyzer
- simple analyzer + stop token filter
- 옵션
- stopwords : 제외시킬 문구 종류
- stopwords_path : 제외시킬 문구 정리한 파일 경로
Keyword Analyzer
- 아무짓도 하지 않는 분석기
- 토큰화도안한다 그냥 그대로 뱉어냄
Pattern Analyzer
- 정규표현식을 사용하는 분석기
- Pattern Tokenizer + Lower case filter + Stop token filter
- 옵션
- pattern : 토큰화 할 표현식
- default : \W+ (영문 단어이다.)
- flags : 정규표현식 flag들
- pipe(
|)로 여러개 사용가능
- pipe(
- lowercase : 소문자화 여부
- stopwords : 제외문자
- stopwords_path : 제외문자 설정파일 경로
- pattern : 토큰화 할 표현식
Language Analyzers
- 다국어 분석기.
- 한국어는 없다…
Fingerprint Analyzer
- fingerprinting algorithm을 이용한 분석기
- 토큰화 과정 중 중첩제거, 정렬, 확장캐릭터제거, 소문자화, 합침 등등을 수행한다.
- standar tokenizer + lowercase token filter + ascii folding token filter + stop token filter + fingerprint token filter
- 옵션
- separator : 구분자
- default : space
- max_ouput_size : 최대 토큰 사이즈
- stopwords : 상위참조
- stopwords_path : 상위참조
- separator : 구분자
Custom Analyzer
- 커스텀
- 옵션
- tokenizer : 토크나이저 선택
- char_filter : 캐릭터 필터 선택
- filter : 토큰필터 선택
- position_increment_gap : array의 경우 각 value들을 토큰화 할 때 임의로 position들 사이에 가상의 gap을 주어 검색 시에 서로 다른 배열 간 text 연결시켜 검색 될 수 없게 하는데 이에 대한 gap 값
- default : 100
- 참조 : position_increment_gap
tokenizer 종류
word oriented tokenizer
- Standar tokenizer
- 표준 토크나이저
- 텍스트 구문 별로 토큰화 한다.
- Letter tokenizer
- 단어 토크나이저
- 단어가 아닌 글자들을 제외시키고 토큰화 한다
- Lowercase tokenizer
- 소문자화 시키고 토큰화 한다.
- Whitespace tokenizer
- space 사이로 띄워서 토큰화 한다
- UAX URL Email tokenizer
- url이나 email은 하나의 토큰으로 묶어서 토큰화 한다.
- Classic tokenizer
- 영어에 한정해서 문법 베이스로 토큰화 한다
- Thai tokenizer
- 태국어.. 왜있는지모름…. 노마드들 많아서그런가..
partial word tokenizer
- N-Gram tokenizer
- sliding window 알고리즘 처럼 구분시켜서 토큰화 함.
- Edge N-gram tokenizer
- 위의 N-gram tokenizer 에서 맨 앞의 글자들만 토큰화해서 저장.
Structured Text tokenizer
- Keyword tokenizer
- 토큰화 안함.
- Pattern tokenizer
- 정규표현식을 이용한 토크나이저
- 각종 flag값이 있으며 group옵션 있음
- default group 은 -1 이며 이는 정규표현식에 걸리는 아이를 중심으로 text를 가른다.
- Simple pattern tokenizer
- 위와 같지만 좀더 간단하게 쓰인다.
- 정규표현식에 있는 애들만 골라서 토큰으로 뺀다.
- Char group tokenizer
- 정규표현식보다 성능이 좋으며 특정 몇가지 심볼로 토큰화 한다
- 사용가능한 심볼
- whitespace
- letter
- digit
- punctuation (문장부호)
- symbol
- 특정 캐릭터 설정 가능 ex)
"-"
- Simple Pattern Split Tokenizer
- 정규표현식에 걸리는 애들을 중심으로 갈라서 토큰화함
- Path Tokenizer
- 말그대로 경로를 토큰화해서 가름.
token filters
- 토큰화된 각 텀들을 걸러내는 필터들.
- 너무 많아서 링크만 올린다.
- 필요할 때 찾아서 쓴다.
- script 사용 하는 필터들도 있어서 각종 커스텀 가능하다.
- 필수는 아니다.
character filters
- analyzer 에서 토큰화 전에 수행하는 캐릭터 필터
- 몇개 없으며 필수는 아니다.
HTML Strip Character Filter
- html태그 없애는 필터
- 인코딩된 캐릭터는 디코딩도 한다.
Mapping Character Filter
- 특정 캐릭터를 다른 캐릭터로 바꾸는 필터
- 키맵형태로 설정한다
Pattern Replace Char Filter
- 정규표현식을 사용한다.
- 특정 정규표현식을 다른걸로 변경해서 저장할 때 사용
- 1세트밖에 안됨.
주의점
- 분석기 설정 시 정규표현식 이용하는 부분들은 정규표현식 사용 형태에 따라 성능저하가 심하게 올 수 있으니 주의해야 한다.